The Kilowatt Calculus
AI’s Thirst for Power & the Race for Sustainable Silicon

AI’s Thirst for Power & the Race for Sustainable Silicon
Neurabridge | Industry Analysis | 23 May 2025
Introduction
Large‑scale AI has pushed computing into an energy‑constrained era. Training a single frontier model can draw megawatts for months, and round‑the‑clock inference now rivals the load of medium‑sized cities. This edition maps the technological pivots from conventional chips to a new kind of computing architecture and the industry‑wide strategies that aim to keep AI growth aligned with a finite global power budget.
Energy has become the primary constraint on AI progress, so transparent power metrics and hardware–algorithm co‑design are now imperative to pushing the technology forward.
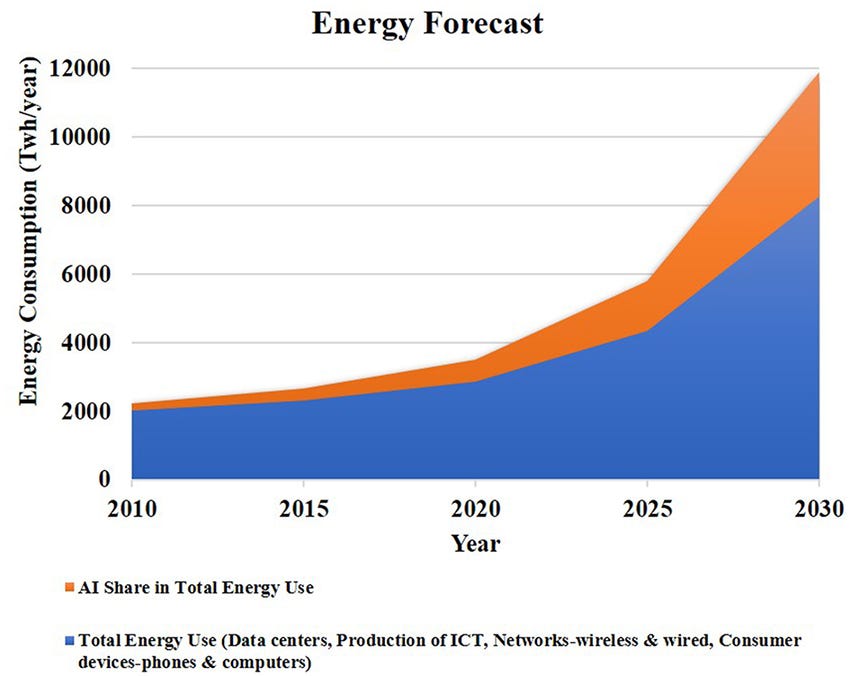
From Petaflops to Petajoules
The new scaling law: every 10× leap in model capability risks a 100× jump in energy unless efficiency improves.
Training cost: Recent foundation models have logged >20 MWh per run.
Inference cost: A single chat service can burn >10 MW continuously.
Grid impact: IEA forecasts data‑centre demand could double by 2030, matching Japan’s current electricity use.
The joule is now as strategic a resource as the parameter for achieving General Artificial Intelligence.
The Incumbent Path
The dominant approach to AI computation, which has taken decades of conventional silicon development, is always moving forward. The limiting factors to model development are often the acquisition of new GPU’s, building large, heavy power consumption facilities, and the boundaries of the mathematics behind matrix multiplication, the key mathematical concept behind LLMs. To move past these limitations, the industry is pursuing several broad strategies to enhance the energy efficiency of established architectures:
Scaling and Architectural Refinements: Leading developers of computational hardware continue to push the boundaries of transistor density, on-chip memory capacity, and clock speeds. Beyond raw scaling, significant efforts are being invested in architectural innovations specifically for AI. These include the integration of specialized processing units, support for lower-precision numerical formats (which reduce data size and computational load), and improved interconnected technologies to minimize data movement bottlenecks.
The goal here is to extract more AI operations per watt from familiar silicon paradigms.
Hardware Specialization for AI Workloads: Recognizing that general-purpose processors may not be optimal for all AI tasks, a trend towards specialized hardware is gaining momentum.
Change #1: Wafer-Scale Integration: One such strategy involves creating massive, single-chip processors that encompass an entire silicon wafer. By integrating vast numbers of cores and large amounts of memory onto a single die, this approach aims to reduce the large scale energy losses associated with inter-chip communication in large distributed systems.
Change #2: Dedicated Inference Accelerators: Another avenue of specialization focuses on inference, the operational phase of AI. These chips are purpose-built for executing trained models with maximum throughput and minimal latency by stripping away unnecessary functionalities and optimizing data flow for the specific patterns of AI inference.

The Neuromorphic Horizon: A Paradigm Shift Towards Adopting Human Brain Architecture
Concurrently with the refinement of conventional systems to resolve the energy crisis the AI industry faces, a more radical alternative is being explored: neuromorphic computing. This field draws inspiration from the human brain's remarkable ability to perform complex computations with extraordinarily low power consumption, being able to perform complex reasoning tasks, memory retention, with a literal fraction of the energy consumption needed for LLMs to operate.
Event-Driven, Asynchronous Processing:
Unlike traditional chips that operate on a global clock, activating vast circuits with every cycle, neuromorphic processors typically employ spiking neurons. These artificial neurons communicate and compute using discrete, asynchronous events (or "spikes"), meaning computational resources are only activated when and where they are needed. This event-driven nature inherently promises substantial energy savings by minimizing idle power consumption and unnecessary computation.
Materializing Brain-Inspired Hardware:
Research and development in neuromorphic hardware have progressed from academic curiosities to tangible silicon. Systems are now capable of simulating billions of spiking neurons, demonstrating orders-of-magnitude improvements in energy efficiency for certain tasks compared to conventional CPUs and GPUs. While primarily used in research, these platforms are proving grounds for a future where AI might operate with biological levels of energy parsimony.
Improvements to Algorithms and Hardware
The quest for energy-efficient AI is not solely a hardware challenge; it's deeply intertwined with the design of AI models themselves:
Conditional Computation in Models: Techniques like Mixture-of-Experts (MoE) are gaining traction. MoE models comprise numerous "expert" sub-networks, only a fraction of which are activated for any given input. This algorithmic sparsity reduces the computational (and thus energy) cost per inference, allowing for larger overall models without a proportional surge in operational energy.
Efficient Sequence Processing: For tasks involving long sequences of data, alternatives to the computationally intensive attention mechanisms of standard transformers are emerging. Linear State-Space Models (LSSMs), for example, aim to process long contexts with linear rather than quadratic scaling of computational cost, offering a more energy-efficient path for certain applications.
Spiking Neural Networks for Mainstream AI: The ultimate synergy lies in designing AI models that are inherently suited to neuromorphic hardware. The development of Spiking Large Language Models (Spiking LLMs) represents early but crucial steps in this direction, attempting to translate the power of modern AI architectures into the event-driven, low-power domain of spiking computation.
This co-evolution is critical. Hardware innovations can enable more efficient execution of existing models, while algorithmic breakthroughs that reduce computational demand can make even conventional hardware more sustainable and open new avenues for neuromorphic implementations.
Computation vs Ambition
The AI industry stands at a crossroads where computational ambition must be balanced with energy realism. The future AI hardware landscape will likely be heterogeneous. Optimized conventional architectures will remain vital for intensive training and high-performance inference.
Simultaneously, specialized accelerators will carve out niches for specific workloads, and neuromorphic systems will progressively find applications where extreme energy efficiency is paramount, such as edge computing and continuous learning systems.
Then, beyond chip design, energy savings will come from system-level innovations: more efficient power delivery and cooling in data centers, intelligent workload scheduling, and distributed computing architectures that minimize data transit.
The AI industry's journey is no longer solely about achieving new heights of intelligence; it is equally about finding sustainable ways to power that intelligence.
The "Kilowatt Calculus" is becoming a central design constraint, forcing a holistic re-evaluation of algorithms, hardware, and deployment practices.
The collective ire of the global tech community is now directed towards ensuring that AI's transformative potential can ultimately be cheaper than the training of an human counterpart expert, while hoping to usher in an era where the computational power behind artificial intelligence does not cost us a no-return climate tipping point.
Written by Julius Brussee
© 2025 Neurabridge — translating deep‑tech signals into strategic clarity.
Can you pls shoot me an email? I have a question concerning the apple FamilyControls api :)
luca.chrustowski at gmail.com